
분산 메시징 프레임워크 절대 강자, Kafka
1. Kafka란?
- 분산환경에서 대규모 메시지를 안정적으로 전송, 수집, 활용할 수 있도록 도와주는 오픈소스 메시징 프레임워크.
- Broker 모델을 이용한 Publish/Subscriber 구조와 Replication이 가능한 Message Queue를 이용하여 신뢰성있는 메시지의 수집이 가능하다는 것이 주요 특징.
- 하둡에코시스템에서 데이터 수집도구로 활용
- Flume이나 Filebeat 등 기타 스트리밍 도구와 함께 사용 시 신뢰성있는 메시지 수집도구로서 활용성 증가
- 특징: Pub/sub 구조, Replication, Partition Tolarance, Message queue, Zookeeper 의존성
2. 신뢰성 있는 메시지 전달을 가능하게 하는 Kafka 구조
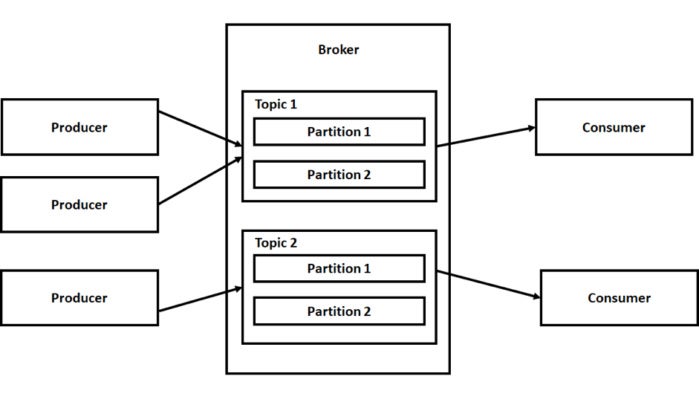
<카프카 핵심 구성요소인 broker와 producer, consumer 구성도>
Kafka Server(Broker)
- 카프카 핵심 엔진, 토픽을 단위로 Partition된 Message Queue를 관리,
- Replication Factor 조정으로 신뢰성(가용성) 보장
- Message Queue(Channel) 로 메시지 관리
Topic
- 카프카에서 메시지를 주고 받기 위해 사용하는 Key
- 토픽단위로 파티션 레벨을 조정할 수 있으며 메시지 전송 시 RR큐 등 지정 전송이 가능
Producer와 Consumer
- Publisher와 Subscriber, 카프카에서는 프로듀서와 컨슈머라는 용어를 사용
- Java API를 통해서 손쉽게 구현 가능
- Flume, Filebeat 등에서 제공하는 Kafka Sink를 이용 Producer 연결 가능
Zookeeper
- 카프카 서버의 자원을 관리하는 기반 모듈, 카프카는 기본적으로 Zookeeper 위에서 동작
3. Kafka가 다른 메시지 수집 도구와 다른 점
- 카프카는 수집된 로그, 메시지 정보를 디스크에 저장
- Pub/Sub 구조로 실시간 푸쉬 방식이 아닌 Consumer가 폴링하는 방식으로 동작
- Flume 같은 메모리 기반 스트리밍 데이터 수집 도구보다 속도는 느릴 수 있으나 상대적으로 신뢰성이 높음
카프카 공식 페이지
카프카 위키백과
https://ko.wikipedia.org/wiki/%EC%95%84%ED%8C%8C%EC%B9%98_%EC%B9%B4%ED%94%84%EC%B9%B4
이 포스트는 IT토픽의 주요 내용과 핵심 키워드를 간략히 설명하는 것이 목적으로, 디테일한 내용에 대해서는 깊이 다루지 않습니다.
'IT Contents > IT Topic' 카테고리의 다른 글
| 양자 컴퓨터는 어떻게 조작된 기억을 우리 뇌에 심을 수 있을까 (0) | 2021.01.28 |
|---|---|
| [해외기사리뷰] iOS 14.4 로 당장 업데이트 하세요. (0) | 2021.01.27 |
| 패션부문 AR/VR 서비스 콘텐츠 기술 동향, 수학 알고리즘 기반의 코딩교육, 주간기술동향 1883호 (0) | 2019.02.16 |
| AR/VR/MR 동향 및 전기차 충전 기술, 주간기술동향 1882호 리뷰(2019.02.06) (1) | 2019.02.11 |
| 가상/증강/혼합현실, 차세대 모빌리티, 임플랜터블, 주기동 1881호 리뷰 (0) | 2019.01.31 |





최근댓글